
前言 RocketMQ是阿里巴巴旗下一款开源的MQ框架,经历过双十一考验、Java编程语言实现,有非常好完整生态系统。RocketMQ作为一款纯java、分布式、队列模型的开源消息中间件,支持事务消息、顺序消息、批量消息、定时消息、消息回溯等,总之就是葛大爷的一句话 核心概念 NameServer:可以理解为是一个注册 […]
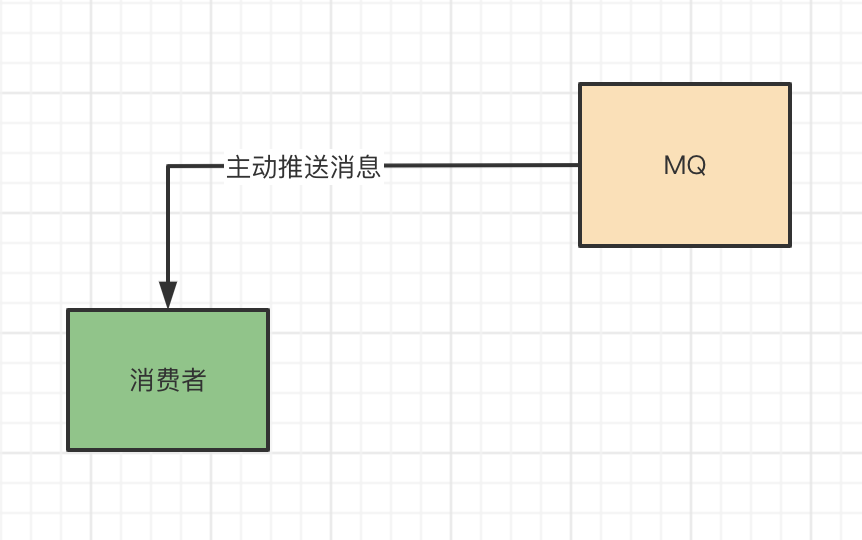
MQ消费方式 消费方式就是指消费者如何从MQ中获取到消息,分为两种方式,push(推方式)和pull(拉方式)。 1、push(推方式) push,顾名思义,就是推的意思。就是当MQ收到生产者产生的消息的时候,会主动将消息推送到消费者进行消费,这种模式就叫push,也就是MQ将消息推给到消费者的意思。 push模式 p […]

背景 我们使用RocketMQ时,一般Consumer启动都是使用的@PostConstruct注解。(@PostConstruct:用于在执行任何初始化时执行依赖注入后需要执行的方法。),或者使用bean的方式配置。 配置如下: 生产者配置 在配置类中配置所有生产者,在业务中注入使用,将生产者的启动和销毁绑定到 Be […]

Redis不需要Leader这个观点其实有歧义,是不准确的,题目的问题本质其实是涉及数据分片、数据复制一致性。 1、Redis Cluster 架构 在Redis3.0版本开始,Redis引入了一种去中心化的集群架构,采用预分片的模式,一个集群中所有节点总共对应16384个槽位,在对一个key进行写入时,首先对key取 […]

1 什么是kafka Kafka是分布式发布-订阅消息系统,它最初是由LinkedIn公司开发的,之后成为Apache项目的一部分,Kafka是一个分布式,可划分的,冗余备份的持久性的日志服务,它主要用于处理流式数据。 2 为什么要使用 kafka,为什么要使用消息队列 缓冲和削峰:上游数据时有突发流量,下游可能扛不住 […]

1、面试场景与面试技巧 金三银四招聘季,一位粉丝朋友最近在蚂蚁金服第二轮面试时遇到这样一个问题:如果MQ消费遇到瓶颈时该如何处理?。 横向扩容,相比很多读者与我这位朋友一样会脱口而出,面试官显然不会满意这样的回答,然后追问道:横向扩容是堆机器,还有没有其他办法呢? 在面试过程中,个人建议大家在听到问题后稍作思考,不要立 […]
最近评论
小林先森 发布于 40 分钟前(05月01日)
李锋镝 发布于 1 天前(04月30日)
李锋镝 发布于 1 天前(04月30日)
李锋镝 发布于 1 天前(04月30日)
夜七笔记 发布于 2 天前(04月29日)
